
در سالهای اخیر، سرعت رشد فناوریهای مبتنی بر هوش مصنوعی، مدلهای زبانی بزرگ (LLM) و پردازشهای HPC بهقدری افزایش یافته که زیرساختهای سنتی دیتاسنتر دیگر پاسخگوی نیاز سازمانها نیستند. امروز کسبوکارها بهدنبال پلتفرمهایی هستند که بتوانند علاوه بر ارائه قدرت پردازشی بالا، مقیاسپذیری، بهرهوری انرژی و مدیریت سادهتری را نیز فراهم کنند.
در همین راستا، NVIDIA با معرفی NVIDIA H200 NVL نسل جدیدی از شتابدهندههای AI سازمانی را وارد بازار کرده است؛ پلتفرمی مبتنی بر معماری Hopper که با تمرکز بر استنتاج مدلهای هوش مصنوعی، پردازشهای سنگین HPC و زیرساختهای مدرن AI طراحی شده است.
H200 NVL تنها یک GPU قدرتمند نیست؛ بلکه بخشی از یک اکوسیستم کامل شامل NVLink ، شبکههای پرسرعت Spectrum-X، فناوریهای GPUDirect و معماری مرجع NVIDIA Enterprise RA محسوب میشود که هدف آن، سادهسازی استقرار AI در مقیاس دیتاسنتری است.
این پلتفرم با حافظه HBM3e پرظرفیت، پهنای باند بسیار بالا و قابلیت ارتباط 4-Way NVLink، امکان اجرای مدلهای بزرگتر، پردازش سریعتر دادهها و دستیابی به توان عملیاتی بالاتر را فراهم میکند. از سوی دیگر، طراحی PCIe دو اسلاته و معماری هواخنک آن باعث شده سازمانها بتوانند بدون نیاز به تغییرات گسترده در زیرساخت دیتاسنتر، وارد نسل جدید پردازشهای AI شوند.
در این مقاله، به بررسی کامل قابلیتهای NVIDIA H200 NVL، معماری مرجع NVIDIA Enterprise RA، فناوریهای ارتباطی و شبکهای، و همچنین روشهای بهینه استقرار این پلتفرم در مقیاس سازمانی میپردازیم تا ببینیم چرا H200 NVL میتواند یکی از مهمترین انتخابهای آینده دیتاسنترهای مبتنی بر هوش مصنوعی باشد.
استقرارNVIDIA H200 NVL در مقیاس سازمانی با معماری مرجع جدید Enterprise
ماه گذشته و در جریان رویداد Supercomputing 2024، شرکت NVIDIA بهصورت رسمی از پلتفرم جدید NVIDIA H200 NVL رونمایی کرد؛ نسل تازهای از معماری Hopper که با تمرکز ویژه بر نیازهای سازمانی، پردازشهای هوش مصنوعی و HPC طراحی شده است.
پلتفرم H200 NVL بهعنوان یکی از پیشرفتهترین راهکارهای AI سازمانی، عملکرد شتابیافتهای را برای طیف گستردهای از بارهای کاری ارائه میدهد؛ از مدلهای زبانی بزرگ (LLM) و عاملهای هوش مصنوعی گرفته تا تحلیلهای پیچیده HPC، تحقیقات پزشکی، شناسایی تهدیدات امنیتی و تحلیل دادههای مالی.
یکی از مهمترین مزیتهای H200 NVL، طراحی دو اسلاته PCIe و توان مصرفی 600 وات آن است؛ موضوعی که به سازمانها اجازه میدهد بدون نیاز به زیرساختهای پیچیده خنکسازی مایع، از معماریهای هواخنک و انعطافپذیر در دیتاسنتر استفاده کنند. این ویژگی، H200 NVL را به گزینهای بسیار جذاب برای شرکتهایی تبدیل میکند که بهدنبال توسعه زیرساخت AI در مقیاس بالا، اما با هزینه و پیچیدگی کمتر هستند.
در این مقاله، نگاهی خواهیم داشت به نوآوریهای کلیدی H200 NVL، بهترین پیکربندیهای پیشنهادی برای سرور و شبکه، و همچنین روشهای بهینه استقرار در مقیاس وسیع بر پایه معماریهای مرجع سازمانی NVIDIA Enterprise RA.
شتابدهی AI در سرورهای سازمانی با NVIDIA H200 NVL
NVIDIA H200 NVL بهعنوان یک پلتفرم تخصصی برای توسعه و استقرار بارهای کاری AI و HPC طراحی شده است. این GPU قدرتمند میتواند در سناریوهای متنوعی مورد استفاده قرار گیرد؛ از چتباتها و AI Agentهای سازمانی گرفته تا تشخیص تقلب مالی، تحقیقات حوزه سلامت، تحلیل دادههای لرزهای و پردازشهای علمی سنگین.
بر اساس اطلاعات منتشرشده توسط NVIDIA، پلتفرم H200 NVL در مقایسه با نسل قبل یعنی NVIDIA H100 NVL تا 1.7 برابر عملکرد سریعتر در پردازش مدلهای زبانی بزرگ (LLM Inference) و تا 1.3 برابر عملکرد بهتر در پردازشهای HPC ارائه میدهد. این بهبود عملکرد، H200 NVL را به یکی از مهمترین گزینههای بازار برای زیرساختهای AI سازمانی تبدیل کرده است.
در ادامه مقاله، جزئیات بیشتری از فناوریها و نوآوریهای معماری H200 NVL را بررسی خواهیم کرد.
ارتقای چشمگیر حافظه در NVIDIA H200 NVL
کارت گرافیک NVIDIA H200 NVL از همان معماری قدرتمند Hopper که در NVIDIA H100 NVL استفاده شده بهره میبرد، اما نقطه تمایز اصلی آن، ارتقای قابلتوجه در بخش حافظه است.
در H200 NVL، انویدیا از حافظه نسل جدید HBM3e با ظرفیت 141 گیگابایت استفاده کرده که نسبت به H100 NVL حدود 1.5 برابر ظرفیت بیشتر و 1.4 برابر پهنای باند بالاتری ارائه میدهد. این ارتقا بهمعنای آن است که مدلهای بزرگتر AI میتوانند مستقیماً روی یک GPU اجرا شوند و دادهها نیز با سرعت بسیار بیشتری بین حافظه و پردازنده جابهجا شوند.
نتیجه این بهبودها، افزایش محسوس Throughput و پردازش تعداد بیشتری Token در هر ثانیه است؛ موضوعی که برای مدلهای زبانی بزرگ (LLM)، پردازشهای Generative AI و استنتاج در مقیاس سازمانی اهمیت بسیار بالایی دارد.
از سوی دیگر، ظرفیت حافظه بیشتر این امکان را فراهم میکند که پارتیشنهای بزرگتری از قابلیت MIG (Multi-Instance GPU) ایجاد شود. این ویژگی به سازمانها اجازه میدهد چندین بار کاری مستقل را بهصورت همزمان روی یک GPU اجرا کنند؛ قابلیتی که برای محیطهای Cloud، سرویسهای AI اشتراکی و زیرساختهای Multi-Tenant یک مزیت کلیدی محسوب میشود.
قابلیتهای جدید NVLink؛ جهش در ارتباط GPUها
یکی دیگر از مهمترین نوآوریهای NVIDIA H200 NVL، پشتیبانی از نسل جدید ارتباطات NVLink است.
H200 NVL از اتصال 4-Way NVLink پشتیبانی میکند که پهنای باندی تا 1.8 ترابایت بر ثانیه ارائه میدهد. این معماری امکان دسترسی به مجموع 564 گیگابایت حافظه HBM3e را فراهم میکند؛ ظرفیتی که در مقایسه با پیکربندی 2-Way NVLink در H100 NVL، حدود 3 برابر حافظه بیشتر در اختیار سیستم قرار میدهد.
علاوه بر این، H200 NVL قابلیت استفاده از پل ارتباطی 2-Way NVLink را نیز دارد که پهنای باند ارتباط GPU به GPU را به 900 گیگابایت بر ثانیه میرساند؛ یعنی:
- 50٪ سریعتر از H100 NVL
- و حدود 7 برابر سریعتر از PCIe Gen5
این سطح از پهنای باند باعث میشود GPUها بتوانند دادهها را با تأخیر بسیار کم و سرعت فوقالعاده بالا با یکدیگر تبادل کنند؛ قابلیتی حیاتی برای:
- آموزش مدلهای بزرگ AI
- پردازشهای HPC
- شبیهسازیهای سنگین
- و استنتاج همزمان در مقیاس وسیع
در عمل، NVLink جدید در H200 NVL یکی از مهمترین دلایلی است که این پلتفرم را به گزینهای ایدهآل برای نسل آینده دیتاسنترهای AI تبدیل میکند.
| Improvement | NVIDIA H200 NVL | NVIDIA H100 NVL | Feature |
| 1.5x capacity | 141 GB HBM3e | 94 GB HBM32 | Memory |
| 1.4x faster | 4.8 TB/s | 3.35 TB/s | Memory Bandwidth |
| 3x faster | way (1.8 TB/s)-4 | 2way (600 GB/s)- | Max NVLink (BW) |
| 3x larger | GB 564 | GB188 | Max Memory Pool |
همراه با NVIDIA AI Enterprise؛ زیرساخت کامل برای توسعه AI سازمانی
یکی از مهمترین مزیتهای NVIDIA H200 NVL، ارائه اشتراک ۵ ساله NVIDIA AI Enterprise بهصورت پیشفرض است؛ پلتفرمی ابری و سازمانی که مجموعهای کامل از ابزارها، Frameworkها، SDKها و Microserviceهای اختصاصی NVIDIA NIM را در اختیار تیمهای توسعه قرار میدهد.
این مجموعه نرمافزاری با هدف سادهسازی فرآیند توسعه، استقرار و مدیریت اپلیکیشنهای AI در مقیاس سازمانی طراحی شده و به کسبوکارها کمک میکند بدون درگیری با پیچیدگیهای زیرساختی، سریعتر وارد فاز عملیاتی شوند.
دسترسی به:
- NVIDIA NIM Inference Microservices
- NVIDIA Blueprints
- ابزارهای توسعه AI
- و سرویسهای بهینهسازی مدل
باعث میشود سازمانها بتوانند مدلهای سفارشی هوش مصنوعی را با سرعت بیشتر، عملکرد بهتر و پایداری بالاتر توسعه داده و در محیط عملیاتی اجرا کنند.
در واقع، ترکیب قدرت سختافزاری H200 NVL با اکوسیستم نرمافزاری NVIDIA AI Enterprise، مسیری سریع و بهینه برای ساخت AI Applicationهای سازمانی فراهم میکند؛ آن هم با حداکثر Performance و کمترین پیچیدگی عملیاتی.
پیکربندی پیشنهادی برای NVIDIA H200 NVL
برنامه NVIDIA Enterprise RA اخیراً پشتیبانی از NVIDIA H200 NVL را نیز به معماریهای مرجع خود اضافه کرده است.
هر NVIDIA Enterprise Reference Architecture یا Enterprise RA، مجموعهای کامل از پیشنهادهای سختافزاری و نرمافزاری را برای ساخت زیرساختهای پردازشی شتابیافته، مقیاسپذیر، امن و با عملکرد بالا ارائه میدهد.
این معماریهای مرجع شامل راهنماییهای دقیقی برای:
- انتخاب سرور مناسب
- طراحی کلاستر
- پیکربندی شبکه
- و بهینهسازی زیرساخت AI
هستند تا سازمانها بتوانند بارهای کاری مدرن AI را با بالاترین راندمان اجرا کنند.
معماری مرجع NVIDIA؛ طراحی بهینه برای AI در مقیاس بالا
در قلب هر Enterprise RA، یک سرور بهینهسازیشده و دارای تأییدیه NVIDIA-Certified Systems قرار دارد که بر اساس الگوهای طراحی استاندارد NVIDIA ساخته شده است.
هدف این طراحی، دستیابی به حداکثر عملکرد هنگام استقرار در محیطهای کلاستری و دیتاسنتری است.
در حال حاضر، معماریهای مرجع NVIDIA در سه دسته اصلی ارائه میشوند:
- PCIe Optimized 2-4-3
- PCIe Optimized 2-8-5
- HGX Systems
در مدلهای PCIe Optimized، اعداد نشاندهنده مشخصات اصلی سرور هستند:
- تعداد CPU
- تعداد GPU
- و تعداد کارتهای شبکه
برای مثال، معماری 2-8-5 به این معناست:
- 2 پردازنده
- 8 کارت GPU
- و 5 آداپتور شبکه
معماری مرجع جدید NVIDIA برای H200 NVL نیز بر پایه طراحی PCIe Optimized 2-8-5 توسعه یافته است؛ ساختاری که برای بارهای کاری سنگین AI، پردازشهای LLM و زیرساختهای AI سازمانی در مقیاس بالا بهینه شده است.
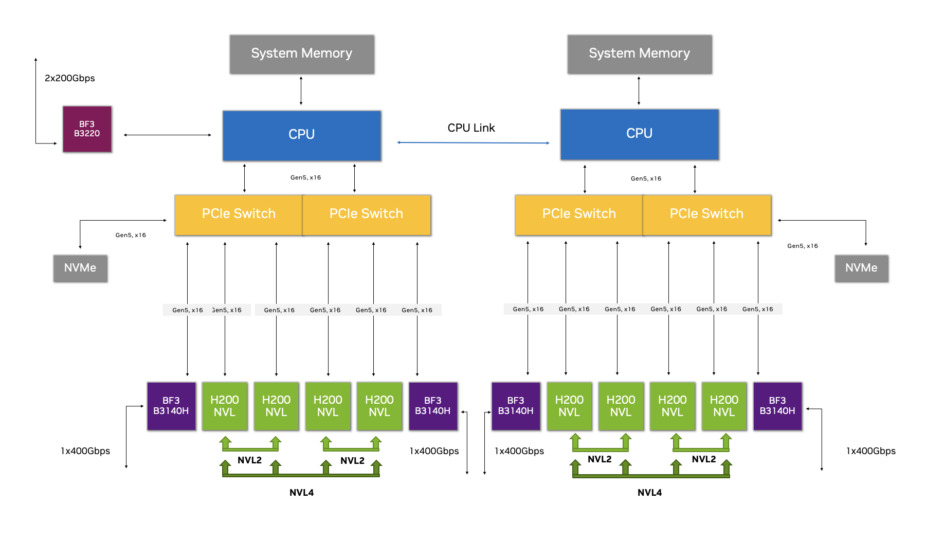
چه چیزی این پیکربندی را متمایز میکند؟
معماری PCIe Optimized 2-8-5 مبتنی بر NVIDIA H200 NVL تنها یک پیکربندی قدرتمند نیست؛ بلکه ساختاری مهندسیشده برای دستیابی به حداکثر راندمان در پردازشهای AI و HPC محسوب میشود.
این معماری با هدف کاهش Latency، کاهش مصرف منابع CPU و افزایش پهنای باند شبکه طراحی شده است؛ موضوعی که در پردازشهای Real-Time و بارهای کاری سنگین AI اهمیت فوقالعادهای دارد.
راز عملکرد بالای این ساختار، ایجاد چندین مسیر انتقال داده (Data Pathway) برای بهینهسازی ارتباط GPU به GPU است؛ مسیری که باعث میشود دادهها سریعتر، مستقیمتر و با سربار کمتر جابهجا شوند.
NVLink؛ ارتباط فوقسریع میان GPUها
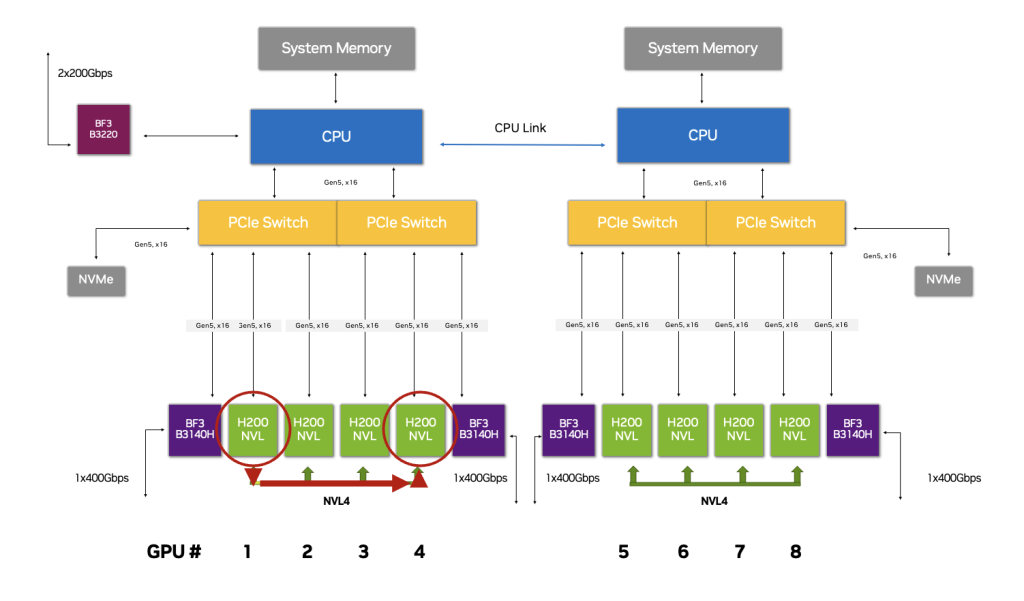
اولین مسیر ارتباطی، فناوری NVIDIA NVLink است که بهعنوان یک پل ارتباطی پرسرعت میان GPUها عمل میکند.
در این معماری، NVLink امکان ارتباط مستقیم، پرسرعت و با تأخیر بسیار پایین بین GPUهایی که در یک Memory Domain قرار دارند را فراهم میسازد. نتیجه این طراحی، افزایش چشمگیر سرعت تبادل داده در پردازشهای سنگین AI، آموزش مدلهای LLM و محاسبات HPC است.
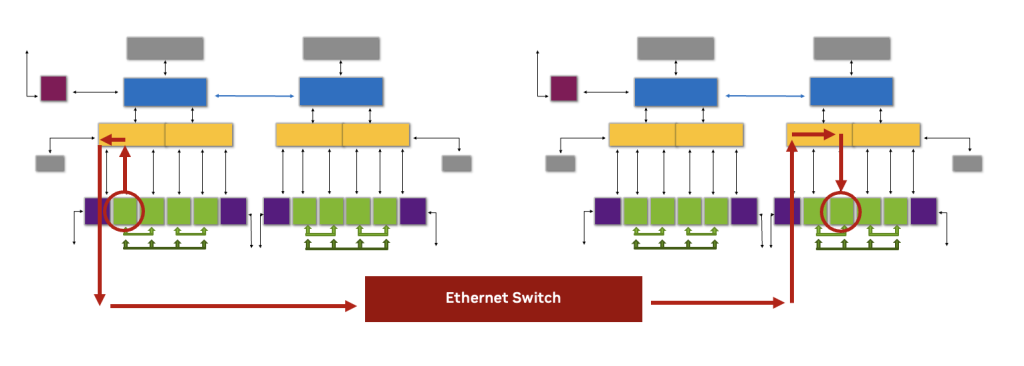
شبکه NVIDIA Spectrum-X؛ ستون فقرات ارتباطات AI Cluster
دومین مسیر ارتباطی، شبکه پرسرعت NVIDIA Spectrum-X است که با فناوری RoCE RDMA یکپارچه شده است.
این ساختار شبکه، یک مسیر ارتباطی کمتأخیر و بسیار بهینه برای تبادل داده میان GPUهای موجود در سطح کلاستر فراهم میکند.
فناوری:
- RoCE (RDMA over Converged Ethernet)
- یا Remote Direct Memory Access
به GPUها اجازه میدهد بدون درگیر کردن CPU، دادهها را مستقیماً از حافظه سیستم یا سایر GPUها دریافت و ارسال کنند؛ قابلیتی که نقش مهمی در افزایش سرعت پردازش و کاهش سربار سیستم دارد.
ترکیب H200 NVL و NVLink؛ جهش در جابهجایی داده
ترکیب قابلیت 4-Way NVLink در NVIDIA H200 NVL با معماری بهینه PCIe Optimized 2-8-5، پلتفرمی با راندمان بیسابقه در انتقال داده ایجاد کرده است.
در این ساختار، ارتباط GPUها چه از طریق NVLink و چه از طریق Spectrum-X و RoCE، میتواند بدون عبور از CPU و حتی بدون وابستگی مستقیم به PCIe Bus انجام شود.
نتیجه این معماری:
- کاهش سربار پردازشی CPU
- افزایش Throughput
- کاهش محسوس Latency
- و بهبود عملکرد در مقیاس کلاستری
خواهد بود؛ موضوعی که برای آموزش مدلهای عظیم AI و پردازشهای بلادرنگ حیاتی است.
NVIDIA GPUDirect؛ دسترسی مستقیم به حافظه GPU
یکی دیگر از فناوریهای کلیدی در این معماری، NVIDIA GPUDirect است.
این فناوری به کارتهای شبکه و درایورهای ذخیرهسازی اجازه میدهد مستقیماً به حافظه GPU دسترسی داشته باشند و دادهها را بدون نیاز به پردازش CPU منتقل کنند.
در نتیجه:
- بار پردازشی CPU کاهش پیدا میکند
- سرعت انتقال داده افزایش مییابد
- و Latency به حداقل میرسد
GPUDirect درواقع مجموعهای از فناوریهای تخصصی NVIDIA است که شامل موارد زیر میشود:
- GPUDirect Storage
- GPUDirect RDMA
- GPUDirect Peer-to-Peer (P2P)
- GPUDirect Video
تمام این قابلیتها از طریق مجموعهای کامل از APIهای بهینه ارائه میشوند تا ارتباط میان GPU، شبکه و ذخیرهسازی با حداکثر سرعت و کمترین تأخیر انجام شود.
در عمل، این فناوریها باعث میشوند زیرساختهای AI مدرن بتوانند دادههای عظیم را با راندمانی بسیار بالاتر مدیریت کنند؛ چیزی که برای نسل جدید دیتاسنترهای AI یک مزیت استراتژیک محسوب میشود.
حداکثرسازی عملکرد NVIDIA H200 NVL در مقیاس سازمانی
پس از بررسی قابلیتهای کلیدی H200 NVL و معماری پیشنهادی سرورها، اکنون زمان آن است که به مهمترین بخش ماجرا برسیم؛ یعنی نحوه دستیابی به حداکثر کارایی در مقیاس دیتاسنتری.
NVIDIA در قالب Enterprise Reference Architecture مجموعهای از فناوریهای مکمل را معرفی کرده که به سازمانها کمک میکند هنگام استقرار خوشهای (Cluster Deployment)، بیشترین بهرهوری را از H200 NVL دریافت کنند. هدف این معماری فقط افزایش قدرت پردازشی نیست؛ بلکه ایجاد یک زیرساخت AI با کمترین تأخیر، بالاترین پهنای باند و بیشترین بازده عملیاتی است.
شبکه NVIDIA Spectrum-X؛ ستون فقرات AI مدرن
در بارهای کاری هوش مصنوعی، سرعت ارتباط میان سرورها و GPUها بهاندازه قدرت پردازش اهمیت دارد. به همین دلیل، NVIDIA در معماری Enterprise RA برای H200 NVL از پلتفرم شبکه NVIDIA Spectrum-X Ethernet for AI استفاده کرده است.
این پلتفرم شامل:
- سوئیچهای قدرتمند Spectrum-4
- و کارتهای شبکه BlueField-3 SuperNIC
میشود که با استفاده از فناوری RDMA مبتنی بر RoCE، کوتاهترین و سریعترین مسیر ارتباطی را میان GPUهای داخل کلاستر ایجاد میکنند.
در این معماری، برای هر دو GPU از نوع H200 NVL یک BlueField-3 SuperNIC اختصاصی با اتصال 400 گیگابیت بر ثانیه در نظر گرفته شده است. این طراحی باعث میشود انتقال داده میان نودهای مختلف با حداقل تأخیر و حداکثر پهنای باند انجام شود؛ موضوعی که برای مدلهای زبانی بزرگ (LLM)، آموزش توزیعشده و پردازشهای HPC کاملاً حیاتی است.
همچنین پردازنده DPU موجود در BlueField-3 امکان پشتیبانی از شبکههای ذخیرهسازی و مدیریتی (North-South Traffic) را نیز فراهم میکند و ساختاری کاملاً بهینه برای زیرساختهای AI سازمانی ایجاد میسازد.
کتابخانه NCCL؛ مغز ارتباطات GPUها
یکی دیگر از فناوریهای کلیدی در معماری H200 NVL، کتابخانه NVIDIA Collective Communications Library یا همان NCCL است.
این کتابخانه بهصورت اختصاصی برای بهینهسازی ارتباط میان چندین GPU طراحی شده و نقش بسیار مهمی در:
- هوش مصنوعی توزیعشده (Distributed AI)
- یادگیری عمیق (Deep Learning)
- و پردازشهای HPC
ایفا میکند.
NCCL بهگونهای طراحی شده که بتواند بهترین مسیر انتقال داده را میان GPUها شناسایی و انتخاب کند؛ چه این GPUها داخل یک سرور قرار داشته باشند و چه در چندین سرور مختلف توزیع شده باشند.
ترکیب NCCL با فناوری NVLink و H200 NVL باعث میشود:
- انتقال داده سریعتر انجام شود
- تأخیر ارتباطات کاهش یابد
- و پردازشهای موازی با راندمان بسیار بالاتری اجرا شوند
این موضوع بهخصوص در سناریوهایی که چندین GPU بهصورت همزمان روی یک مدل AI کار میکنند، اهمیت فوقالعادهای دارد.
AI Agentها؛ جایی که NCCL تفاوت واقعی را نشان میدهد
یکی از مثالهای جذاب برای نمایش قدرت این معماری، اپلیکیشنهای Agentic AI ساختهشده با NVIDIA Blueprints هستند.
این AI Agentها معمولاً از چندین NIM Microservice تشکیل میشوند که روی GPUهای مختلف اجرا شدهاند. در چنین ساختاری، سرعت ارتباط میان GPUها مستقیماً روی عملکرد نهایی سیستم تأثیر میگذارد.
NCCL با بهینهسازی ارتباطات بین این سرویسها، کمک میکند:
- پاسخدهی AI سریعتر شود
- پردازش همزمان مدلها روانتر انجام شود
- و کل زیرساخت AI با کمترین سربار ممکن فعالیت کند
در نتیجه، سازمانها میتوانند نسل جدیدی از سرویسهای هوشمند مبتنی بر AI Agentها را با پایداری و مقیاسپذیری بسیار بالا پیادهسازی کنند.
| قابلیت | فناوری |
| راهکار جامعی که عناصر سختافزاری و نرمافزاری را برای بهینهسازی حجم کار هوش مصنوعی ادغام میکند. Spectrum-X در ترکیب با H200 NVL، انتقال و ارتباط کارآمد دادهها را از طریق سوئیچهای اترنت Spectrum-4، BlueField-3 SuperNICs، کیتهای توسعه نرمافزار Spectrum-X (SDK) و NCCL فراهم میکند. | Spectrum-X (hardware and software) |
| NCCL عملیات ارتباطی بهینهشدهای را برای H200 NVL فراهم میکند. NCCL از توپولوژی آگاه است، قادر به بهینهسازی فناوری اتصال داخلی GPU مانند NVLink است و از طراحیهای توپولوژی بهینهشده برای خطوط راهآهن بهره میبرد که در آن کارتهای شبکه به سوئیچهای برگ خاص متصل میشوند. کتابخانه تخلیه بار NCCL بخشی از NCCL است و امکان تخلیه بار عملیات ارتباطی جمعی به شبکه را فراهم میکند، بار روی CPU را کاهش میدهد و عملکرد را بهبود میبخشد. | NCCL (software) |
| فناوری اتصال داخلی پرسرعت، که نسل چهارم آن در H200 NVL استفاده میشود. NVLink نسل چهارم، پهنای باند بالایی معادل 900 گیگابایت بر ثانیه را برای ارتباط GPU-to-GPU فراهم میکند که به طور قابل توجهی بالاتر از اتصالات داخلی نقطه به نقطه است. | NVLink Bridge (hardware) |
| کیتهای توسعه نرمافزار Spectrum-X با H200 NVL کار میکنند و شامل Cumulus Linux، pure SONiC، NetQ و چارچوبهای نرمافزاری NVIDIA DOCA میشوند. این کیتهای توسعه نرمافزار به صورت تجمیعی کار میکنند تا عملکرد را در بارهای کاری مختلف هوش مصنوعی بدون افت کیفیت تضمین کنند. | Software Development Kits (SDKs) (software) |
| پروتکل شبکهای که انتقال مستقیم حافظه به حافظه را بین سرورها و آرایههای ذخیرهسازی از طریق شبکههای اترنت امکانپذیر میکند و از دخالت CPU جلوگیری میکند. تأخیر در ارتباطات بین سیستمی H200 NVL توسط RoCE کاهش مییابد، در حالی که NVLink زمان پاسخگویی برای ارتباطات درون سیستمی GPU را کاهش میدهد. | RDMA over Converged Ethernet (RoCE) GPU Direct |
ساخت زیرساخت نسل جدید با NVIDIA H200 NVL
NVIDIA H200 NVL با ارائه عملکردی قدرتمندتر و قابلیتهای پیشرفتهتر، نسل جدیدی از شتابدهندههای مبتنی بر معماری Hopper را برای دیتاسنترهای سازمانی معرفی کرده است. این پلتفرم نهتنها توان پردازشی بالاتری برای AI و HPC فراهم میکند، بلکه مسیر توسعه زیرساختهای مدرن هوش مصنوعی را نیز برای سازمانها سادهتر میسازد.
سازمانهایی که بهدنبال ارتقای دیتاسنتر و ورود جدی به نسل جدید پردازشهای AI هستند، اکنون میتوانند از طریق اکوسیستم جهانی شرکای NVIDIA، به پلتفرمهای متنوع مجهز به H200 NVL دسترسی داشته باشند. این موضوع باعث میشود کسبوکارها متناسب با نیاز خود، بهترین معماری و پیکربندی را انتخاب کنند.
در همین راستا، معماری مرجع NVIDIA Enterprise RA برای H200 NVL نیز در اختیار شرکای تجاری قرار گرفته است تا طراحی و پیادهسازی زیرساختهای AI در مقیاس بالا با پیچیدگی بسیار کمتری انجام شود.
این معماری مرجع، مجموعهای از طراحیهای تستشده و توصیههای جامع را ارائه میدهد که شامل:
- پیکربندی بهینه سرورها
- طراحی شبکه
- ارتباطات GPU
- و زیرساختهای مقیاسپذیر AI
میشود.
در واقع، NVIDIA با ارائه Enterprise RA تلاش کرده فرآیند طراحی دیتاسنترهای مبتنی بر H200 NVL را از یک پروژه پیچیده مهندسی، به یک مسیر استاندارد، سریع و قابل اطمینان تبدیل کند؛ مسیری که سازمانها بتوانند با اطمینان بیشتر، زیرساختهای AI آینده خود را توسعه دهند.
نتیجهگیری نهایی
NVIDIA H200 NVL را میتوان یکی از مهمترین گامهای NVIDIA در مسیر توسعه زیرساختهای AI سازمانی دانست؛ پلتفرمی که نهتنها قدرت پردازشی بالایی ارائه میدهد، بلکه با تمرکز بر مقیاسپذیری، بهرهوری و سادگی استقرار طراحی شده است.
افزایش چشمگیر ظرفیت و پهنای باند حافظه HBM3e، قابلیت 4-Way NVLink، پشتیبانی از GPUDirect و یکپارچگی با شبکههای پرسرعت Spectrum-X، باعث شده H200 NVL بتواند پاسخگوی نسل جدید بارهای کاری AI و HPC باشد؛ از مدلهای زبانی بزرگ گرفته تا AI Agentها و پردازشهای توزیعشده در مقیاس وسیع.
در کنار سختافزار قدرتمند، معماری مرجع NVIDIA Enterprise RA نیز نقش مهمی در سادهسازی طراحی و استقرار دیتاسنترهای AI ایفا میکند. این معماری با ارائه طراحیهای تستشده و توصیههای بهینه، پیچیدگی پیادهسازی زیرساختهای مبتنی بر GPU را کاهش میدهد و مسیر توسعه پروژههای AI را برای سازمانها سریعتر و مطمئنتر میسازد.
نکته مهم اینجاست که H200 NVL تنها برای شرکتهای بزرگ فناوری طراحی نشده؛ بلکه راهکاری برای طیف گستردهای از سازمانهاست که میخواهند بدون ورود به زیرساختهای فوقپیچیده و پرهزینه، از قدرت واقعی هوش مصنوعی در مقیاس عملیاتی استفاده کنند.
در نهایت، ترکیب H200 NVL با اکوسیستم نرمافزاری NVIDIA AI Enterprise، شبکههای نسل جدید و معماریهای بهینهشده، نشان میدهد آینده دیتاسنترها به سمت زیرساختهایی حرکت میکند که هوشمندتر، سریعتر و مقیاسپذیرتر از همیشه هستند؛ و NVIDIA H200 NVL دقیقاً برای همین آینده ساخته شده است.
آداک فناوری مانیا با عرضه سرور و استوریج با قیمت و کیفیت مناسب در کنار شماست تا بهترین انتخاب را داشته باشید. با مشاورین فنی ما در تماس باشید تا بهترین پیشنهاد را به شما داشته باشند.


